Microsoft stellt Deep-Learning-Toolkit CNTK bei Github zur Verfügung

Es richtet sich an Entwickler, die Lern-Modelle für Sprach und Bilderkennung entwickeln wollen. CNTK ist seit April 2015 Open Source. Es wurde aber bisher nur auf Microsofts Repository CodePlex bereitgestellt. Nutzer waren damit an Microsofts sogenannte Academic License gebunden.
Microsoft bietet sein Computational Network Toolkit (CNTK), mit dem sich Anwendungen im Bereich des derzeit hochgehandelten Deep Learning entwickeln lassen, Developern nun auch auf Github an. Open Source ist CNTK bereits seit April 2015. Allerdings stand es nur bei Microsofts CodePlex unter der sogenannten Academic License zur Verfügung. Indem es nun bei Github angeboten wird, können es Entwickler unter der MIT-Open-Source-Lizenz nutzen. Damit fallen viele bislang geltende Beschränkungen weg und wird CNTK für Dritte tatsächlich praxisrelevant.
![]()
CNTK war von Microsoft-Forschern für die eigene Arbeit an Sprach- und Bilderkennung entwickelt worden, da sie mit anderen, bereits verfügbaren Tool unzufrieden waren. Was damit möglich ist, zeigte Microsoft im November vergangenen Jahres zusammen mit Wissenschaftlern der Carnegie Mellon University. Die Partner haben zusammen ein System entwickelt, mit dem Maschinen Bilder analysieren können. Ziel ist es Maschinen „beizubringen“ mit Hilfe der aus der Analyse gewonnen Informationen, “natürliche” Fragen so zu beantworten.
Illustriert wurde das anhand eines Foto, das zwei Hunde zeigt, die in einem Fahrradkorb sitzen. Die zu beantwortende Frage war: “Welches Tier sitzt da in dem Fahrradkorb”. “Zuerst würde man in der ersten Informationsschicht die spezifischen Details erfassen – das Fahrrad, den Korb und was in dem Korb ist”, erklärt Microsoft dazu. “Dann würde eine zweite Schicht die fraglichen Schlüsselbereiche genau bestimmen – den Korb – und analysieren, was darin ist. Die Antwort: Hunde.”
Menschen konzentrierten sich auf das, was für die Beantwortung einer Frage erforderlich ist. Ein Computer entscheide mithilfe eines neuralen Netzwerks, welcher Bildauschnitt für die Frage wichtig sei, und unterdrücke irrelevanten Informationen, so Microsoft weiter. Das System erfasse Informationen, ähnlich wie menschliche Augen und das Gehirn, schaue sich die Szene an und stelle Beziehungen zwischen den Objekten her.

Den Microsoft-Forschern zufolge, die CNTK entwickelt haben, könne das Toolkit etwa Start-ups im Bereich Deep Learning ebenso helfen wie etablierten Firmen, die große Datenmengen unmittelbar auswerten wollen. “Mit CNTK haben sie eine Möglichkeit, uns beim nächsten Druchbruch im Bereich Künstlicher Intelligenz zu begleiten”, erklärt Xuedong Huang, Leiter der Sprachforschung bei Microsoft.
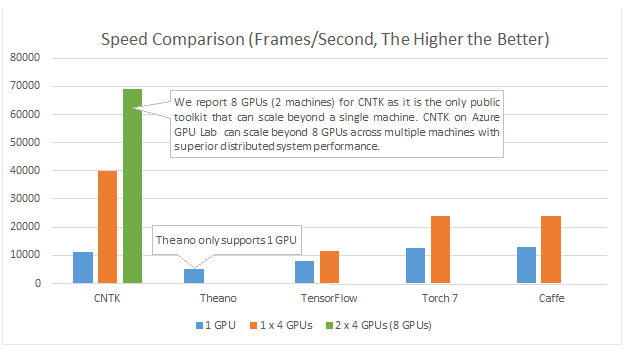
Allerdings haben Firmen inzwischen die Qual der Wahl, mit wem sie sich auf den Weg in die Zukunft machen wollen. Google hatte im November vergangenen Jahrs seinen Ansatz TensorFlow vorgestellt und als Open Source verfügbar gemacht. Kurz zuvor hatte sich der US-Konzern als Gesellschafter am des Deutschen Forschungszentrums für Künstliche Intelligenz (DFKI) beteiligt. Dass DFKI ist für Google vor allem wegen seiner Kompetenz bei Technologien für die Analyse von Bildern, Videos sowie gesprochener und geschriebener Sprache interessant.
Erfahrung in der Zusammenarbeit haben die beiden bereits: So arbeitet etwa Google Translate mit Algorithmen, die in einem DFKI-Projekt entwickelt wurden. In der künftigen Zusammenarbeit zwischen Google und dem DFKI soll eine Software zur Bildanalyse eine Rolle spielen, die das Forschungsunternehmen entwickelt hat. Mit ihr lassen sich kriminelle Inhalte, etwa Kinderpornographie im Internet, automatisch erkennen. Google könnte die Software einsetzen, um illegalen Content in seinen Web-Datenbanken aufzudecken.
Hardware für Künstliche Intelligenz (KI) hat im Dezember Facebook offengelegt. Das Unternehmen kooperiert bei seiner Big Sur genannten KI-Plattform mit Nvidia. Facebook Artificial Intelligence Research (FAIR) war der erste Kunde, der den im November vorgestellten GPU-Beschleuniger Tesla M40 für neuronale Netze nutzt. Die Hardware basiert auf dem von Facebook imitierten Open Compute Project.