Der Stand der Dinge bei Cognitive Computing

Auf der CeBIT Preview hat das Unternehmen umrissen, was es unter kognitiven Computing-Systemen versteht und wie diese in der Lage sind, immer bessere Ergebnisse und Antworten zu liefern. Praxisbeispiele wurden anhand des hauseigenen IBM-Systems Watson geliefert.
IBM hat diese Woche auf einer Presseveranstaltung in München dargelegt, was es unter “Cognitive Computing” versteht. Dazu hat der Konzern anhand seines hauseigenen kognitiven Computing-Systems Watson Praxisbeispiele zu entsprechenden Lösungen vorgestellt. Demnach sollen kognitive Systeme im Allgemeinen die Bedürfnisse von Kunden antizipieren und abhängig vom jeweiligen Kontext möglichst zufriedenstellend bedienen.
![]()
“Cognitive Computing bedeutet, dass entsprechende Systeme unter Zuhilfenahme kontextbasierter Informationen vorausschauend denken und planen können”, erklärte Stefan Riedel, Vizepräsident für den Geschäftsbereich Versicherungen in Europa bei IBM. Ihm zufolge sind kognitive Systeme wie Watson in der Lage, von Interaktionen mit Menschen zu lernen und “evidenzbasierende Antworten” zu liefern, also Antworten, die auf bewerteten und belegten wissenschaftlichen Erkenntnissen beruhen, um so insgesamt bessere Ergebnisse offerieren zu können. Von Interaktionen lernen heißt für IBM konkret, dass Watson wiederholt natürliche menschliche Sprache verarbeiten muss, um die Komplexität von unstrukturierten Daten, etwa in Form von Kommentaren oder E-Mails, verstehen und analysieren zu können.

“Watson kann heute bereits 27 Sprachen sozusagen ‘lesen’ und ‘schreiben’. Unter anderem kann er zum Beispiel auch Japanisch, Portugiesisch und Italienisch sprechen. Digitale Sprachassistenten wie Siri oder Cortana verstehen zwar auch natürliche Spracheingaben, sind aber regelbasierende Programme. Watson integriert zwar ebenfalls grundlegende Regeln, lernt aber durch die Interaktion mit dem Menschen immer weiter dazu”, erläutert Riedel.
So könne Watson etwa Millionen von Textdokumenten oder Bilder innerhalb von Sekunden einlesen, daraus Informationen aggregieren und diese mit bereits vorhandenem Wissen in einen gewichteten Zusammenhang bringen, sie also bewerten. Anschließend präsentiere das System Lösungsvorschläge und verbessere diese Ergebnisse im Laufe der Zeit anhand der Antworten, die es vom Menschen, etwa in Form von Korrekturen, zurückerhalte.
In der Praxis kommt das beispielsweise schon in dem im April 2015 gegründeten Geschäftsbereich IBM Watson Health zum Einsatz, der medizinische Daten für Ärzte und Forscher nutzbar machen soll. So konnten durch die automatisierte Auswertung von mehreren Millionen Artikeln in wissenschaftlichen Zeitschriften Riedel zufolge neue Erkenntnisse bezüglich des Proteins P53 generiert werden, das mit der Entstehung diverser Krebsarten in Verbindung gebracht wird. Watson habe dafür lediglich einige Wochen benötigt, Forscher hätten dafür sonst Jahre gebraucht.
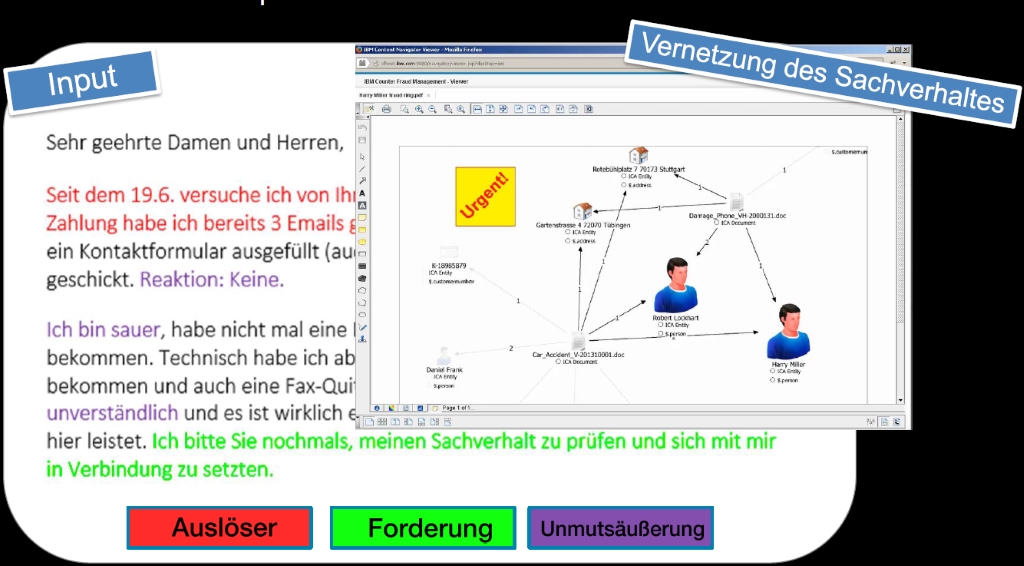
Ebenso soll Watson künftig verstärkt im Kundenservice und in der Finanzbranche zum Einsatz kommen. Gleiches gilt auch für die Versicherungsbranche, in der Watson laut Riedel bereits für das Interpretieren und Bewerten von E-Mail-Korrespondenz eingesetzt wurde und aus dem Input beispielsweise eine Unmutsäußerung beziehungsweise Beschwerde “herauslesen” konnte.
Darüber hinaus sei Watson in der Lage, Personen und Objekte auf Bildern zu erkennen und diese innerhalb weniger Sekunden zuzuordnen. Nutzer können das anhand einer Online-Bilderkennung ausprobieren, die es erlaubt, dort Fotos hochzuladen und diese von Watson klassifizieren zu lassen, indem das System einzelne Elemente wie dargestellte Objekte, Hintergrundfarbe und Art der Szene analysiert.
Stefan Riedel brachte hierbei auch das Beispiel eines Bildes einer Baustelle. Watson habe es nicht nur als solches klassifizieren können, sondern sei aufgrund des ihm schon vorliegenden Wissens auch fähig gewesen, unmittelbar einen situationsbedingten Zusammenhang zwischen der Baustelle und den dort zu treffenden Sicherheitsvorkehrungen herzustellen. So konnte das kognitive System erkennen, dass einige Bauarbeiter auf dem Foto keine Helme oder unsicheres Schuhwerk trugen und damit gegen Vorschriften verstießen.

Im Dezember hatte IBM in München die weltweite Zentrale der neu gegründeten Geschäftseinheit Watson IoT eröffnet. Seine Entscheidung für den Standort München begründete IBM damals mit den gerade für das Thema Internet der Dinge in der Stadt besonders günstigen Voraussetzungen. Dazu gehöre nicht nur die räumliche Nähe zu großen Firmen aus der Automobil- und Versicherungsbranche – zwei Branchen, in denen IBM für IoT für besonders großes Potenzial sieht -, sondern man könne auch auf hervorragende Universitäten zurückgreifen.
Laut Harriett Green, Leiterin der neuen IBM-Sparte Watson IoT, werden derzeit fast 90 Prozent der durch “Dinge” generierten Daten nicht genutzt. Um aus ihnen wertvolle und aussagekräftige Informationen zu machen, brauche es eine Plattform und die Möglichkeit, Applikationen für die jeweiligen Bedürfnisse schnell und einfach zu schreiben. “Es gilt, aktuelle Daten zu nutzen, sie in Beziehung zu historischen Informationen zu setzen und damit möglicherweise noch unbekannte Korrelationen zu entdecken. So werden neue Einsichten und ein neues Verständnis für Zusammenhänge geschaffen, von denen Unternehmen und Gesellschaft profitieren”, so Green im Zuge der Einweihung.
In einem aktuellen Video auf Youtube veranschaulicht IBM die natürlichsprachliche Interaktion von Watson mit einem Menschen.